微服务 - 服务发现与注册
本博文是原书第6章节的读书笔记。内容主要包括:
- 为什么在云原生应用中,服务发现是一个重要的话题?
- 服务发现 vs (单独的)负载均衡(服务器)
- 配置SpringNetflixEurekaServer
- 使用Eureka进行服务注册
- 使用SpringCloudLoadBalancer库进行客户端的负载均衡
在分布式系统中,需要找到服务的位置与其进行沟通,这一概念在分布式概念之初就被作为”服务发现”所提出了。 而其即可以是简单地通过维护一个property文件来罗列所有的服务地址,也可以是一整个复杂的标准化系统。
对于基于云的微服务应用,服务发现是一个重要的话题,两点原因如下:
- 水平拓展或缩放 - 微服务的服务数量会随着时间的推移而变化,因此需要一个机制来动态地发现服务。
- 弹性 - 弹性宏观上指的是一个系统在不影响业务的情况下吸收所出现问题的能力。微服务架构中,需要对服务本身的状态十分敏感,防止单点故障。
有了服务发现机制,我们可以在不打搅客户端的情况下轻松地对系统进行水平拓展或缩放,因为客户端根本不需要知道服务的数量或位置。另一个好处就在于 服务发现机制可以帮助我们实现弹性,因为它可以在服务出现故障时(或被完全占用时)自动地将客户端请求重定向到其他可用的服务上。
也许这听上去有点复杂,你可能会思考为什么不直接使用那些久经考验的方法例如DNS或负载均衡器来解决这个问题呢? 在之后的内容中,我们会分析这些方法为什么不适用于微服务架构,特别是基于云的微服务架构。而后我们将使用SpringCloudNetflixEureka来实现服务发现。
Where’s my service?
如果你有一个应用程序需要调用分布在多个服务器上的资源,那么自然地,它需要找到这些资源的物理位置。
在非云的世界中,服务位置的发现通常是通过DNS与网络负载的组合实现的。下面是一个简单的图例:
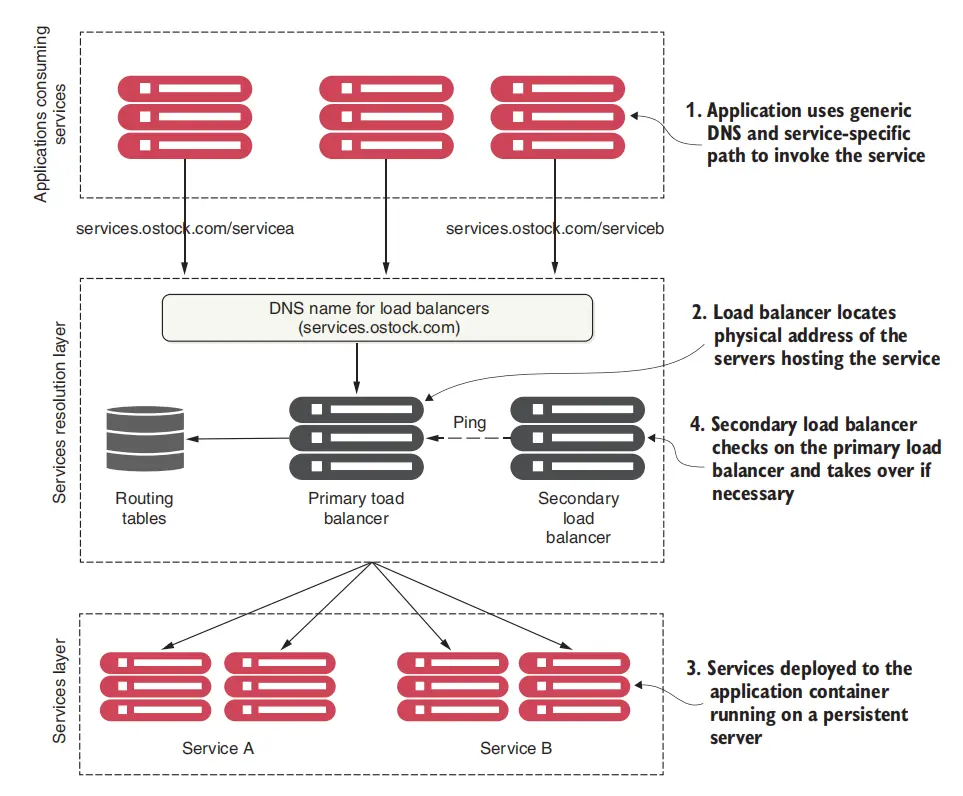
在传统情景中,当一个应用程序需要调用另一个位于不同组织的服务时, 其会尝试通过使用一个通用的服务DNS名称与一个特定地表示服务的名称来发现服务的位置。 该DNS名称将会由一个商业负载均衡器解析。这个负载均衡器会将在Routing Table中挑选出一个服务实例的IP地址,然后将请求转发到该IP地址上。
听上去和我们介绍的服务发现机制所要完成的事情很相似,事实也确实如此,DNS与负载均衡器的组合算是一种传统的服务发现机制。 但是请注意传统情景下的一些特点:
- 服务的位置通常是静态的(服务的数量不会增加或者减少)
- 服务是持续性的(服务的生命周期是长期的,如果一个服务down了之后,其应当恢复如初,复用之前的ip配置)
- 为了实现某种形式的高可用,通常有一个闲置的二级负载均衡组件
拥有上述特点的DNS + 网络负载均衡器的组合在 相对固定服务数量的场景中(通常是数据中心内)是非常有效的,但是在云原生应用中,这种组合的效果就不是很好了。
- 尽管可以做到高可用,但本质上负载均衡器仍然是一个单点故障,一个集中的chokepoint
- 负载均衡本质上是我们服务的一个proxy,这意味着需要任务定义路由规则,这是一个非常繁琐的过程,其添加了额外的复杂性
- 大多数负载均衡器的配置是静态的(使用一个集中的数据库存储路由规则),这意味着当服务的数量发生变化时,需要手动地更新负载均衡器的配置(不论是直接操作数据库,还是call api)
- 负载均衡本身也限制了服务的水平拓展,因为负载均衡服务器本身也是有自己的容量(性能)限制的,并且通常商用的负载均衡组件是昂贵的
当然,这些问题在传统的数据中心中并不是很明显,因为服务的数量通常是固定的,而且服务的生命周期也是长期的。 并且,负载均衡器在集中处理SSL终端与服务端口安全性上有其优势。 但是在云原生应用中,使用这种组合是不实际的。
Service discovery in the cloud
解决云原生微服务应用中服务发现的问题,需要一个新的方法。这个方法需要满足以下要求:
- 高可用 - 服务发现机制本身也应该可以进行集群化,以避免单点故障
- Peer-to-peer - 集群化中的每一个服务发现组件需要共享状态
- 均衡负载的 - 服务发现机制需要能够负载均衡地将请求分发到可用的服务上
- 弹性 - 为保证弹性,客户端需要缓存服务发现组件提供的服务地址,以避免在服务发现组件不可用时无法访问服务
- 容错性 - 服务发现组件需要能侦测到服务节点的健康状态,以便在服务节点不可用时将其从服务列表中移除( 这一过程应该是非人为干预的)
接下来的内容中将展示
- 在云原生中的服务发现组件如何工作的概念模型
- 客户端的服务缓存与负载均衡,其使得当服务发现组件不可用时,客户端仍然可以访问服务
- 如何实现一个使用SpringCloudNetflixEureka的服务发现组件与客户端
服务发现的架构
在探讨服务发现的架构之前,我们先要熟悉一下常用的核心概念:
- 服务注册 一个服务实例如何将自己注册到服务发现组件中
- 服务发现 客户端如何从服务发现组件中获取服务的位置信息
- 信息共享 (服务发现)节点之间如何共享服务(实例的健康)信息
- 健康检查 服务发现组件如何检测服务节点的健康状态
服务发现架构的最首要目标是让服务实例本身将其物理地址提供到服务发现组件中,让服务注册与管理这一过程不需要任何人为干预。
下面是一个简单的图例:
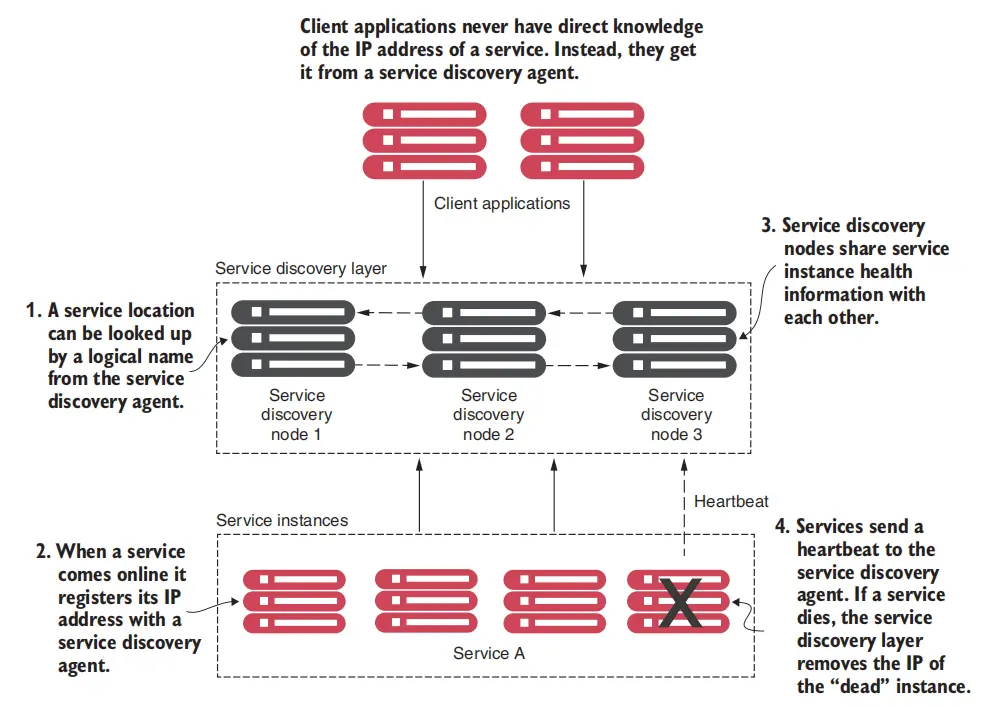
图上就是包含之前提到的四个关键概念的一个实现流程。当一个服务实例启动时,其会将自己的物理地址(与更多关于自身的信息)注册到服务发现组件中。 通常其只会向一个服务发现组件注册,然后服务发现集群中的其他节点会对信息进行同步。(针对实现的不同,这一过程可能是通过硬编码的方式,也可能是通过某种协议来实现的, 感兴趣的推荐阅读 Consul’s “Gossip Protocol” or Brian Storti’s post, “SWIM: The scalable membership protocol”)
最终,服务实例向服务发现组件 提交自己/获取其他实例 的信息。 而服务消费端具体如何使用服务信息有不同的做法。
一种直接的做法是每当想要调用服务时,都向服务发现组件请求服务的信息(也就是上面一张图的直接流程)。这种做法的缺点是,服务发现组件可能会成为一个瓶颈与潜在的单点故障。 所以另一个更推荐的做法是,客户端缓存服务发现组件提供的信息,然后使用负载均衡算法从缓存中选择一个服务实例。
一个简单的图例如下:
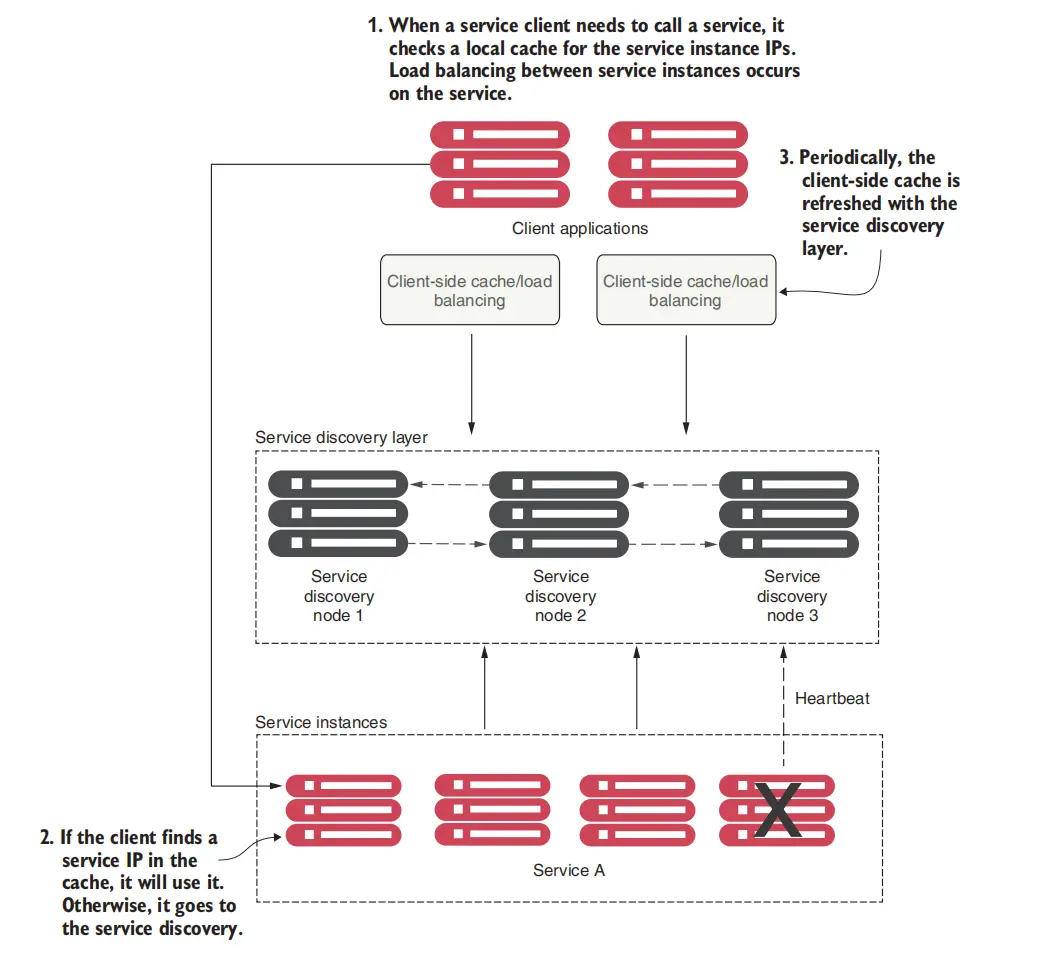
这种做法也称为客户端负载均衡。 首先当客户端有消费需求是,从服务发现组件中直接拉取对应服务的所有实例信息,然后缓存到本地。 然后使用负载均衡算法从缓存中选择一个服务实例,对服务进行调用。如果调用失败,那么客户端首先自然会尝试不同的服务实例,并更新缓存中的服务实例信息。 以及在这些逻辑之外,不论具体情况都需要时不时更新缓存中的服务实例信息。
注意在客户端负载均衡消费 服务发现的信息 这一方法中,尽管不需要,但客户端最终还是直接拥有了所有服务实例的信息(为了减少对服务发现组件的依赖)。这里提醒一下, 服务发现组件是面向系统内部的,所谓的客户端也是系统内部的微服务组件消费其他的微服务组件,而不是客户端浏览器或者移动端应用。客户端仍然在原则上不需要也不应该直接访问服务实例。 为实现这一点一般单独使用GateWay网关服务,这一点之后的章节会讲到。
作者之后展示了其要实现的具体的服务发现组件的架构图,该图已经很好地进行了说明,所以这里不多做赘述。
Building our Spring Eureka server
作者在书中的步骤很详尽,不过我个人就不那么具体地展开了,仅罗列关键步骤
首先,Eureka自然是一个单独的微服务组件(集群),所以需要一个单独的SpringBoot项目来实现。 使用SpringInitializer是创建一个SpringBoot项目的最佳实践,添加基本依赖如Actuator与ConfigClient等用于监控与拉取配置信息。 最关键的依赖自然是EurekaServer本身。 一个小细节是EurekaServer附带的Ribbon依赖用于实现客户端负载均衡,但其不再更新已进入仅维护模式,所以作者使用了SpringCloudLoadBalancer来替代。
项目创建完成之后,在bootstrap.properties/yaml中添加基本配置:应用名,配置中心的地址,并将ribbon关闭以使用SpringCloudLoadBalancer。
接着是重要的关于Eureka本身的配置,注意该配置应该从配置中心拉取,其内容如下:
1
2
3
4
5
6
7
8
9
10
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
server:
waitTimeInMsWhenSyncEmpty: 5
eureka.instance.hostname:EurekaServer的主机名,这里使用localhost,但在实际生产环境中应该使用真实的主机名。eureka.client.registerWithEureka:是否将自己注册到EurekaServer中,这里设置为false.eureka.client.fetchRegistry:是否从EurekaServer中获取注册信息(作为缓存本地存储),这里设置为false.但在之后的客户端配置中,你会看到这个配置是true的。eureka.client.serviceUrl.defaultZone:EurekaServer的地址,这里使用了${eureka.instance.hostname}与${server.port}来动态获取主机名与端口号。server.waitTimeInMsWhenSyncEmpty:EurekaServer在启动时,如果没有任何服务实例注册,那么它会等待一段时间再启动,这里设置为5ms。
上述最后一个配置是让我们本地测试启动EurekaServer时不用等待太久。因为默认情况下,EurekaServer会等待一段时间(书中版本为5min)再启动,以便等待其他服务实例注册。
以及,与该配置无关的一个补充是,一个正常的服务实例注册到Eureka需要花费约30s的时间,因为Eureka需要确保服务实例有3次心跳,才会将其标记为UP,而每次心跳间隔为10s. (这些数据是书中所使用的Eureka,不确定当你阅读到本博文时Eureka有没有做调整)
接着,最后一个补充就是在启动类上添加@EnableEurekaServer注解,以启用EurekaServer。
Registering services with Spring Eureka
Eureka服务注册服务已经准备好了,接下来是让其他服务实例注册到Eureka中。
首先,需要在服务实例中添加EurekaClient依赖
然后在(configServer的)配置文件中添加spring.application.name作为服务实例的名称。 每一个在Eureka中注册的服务都有两个与之相关的组件,一个是applicationID,一个是InstanceId。 前者就是我们配置的spring.application.name,后者是一个随机生成的ID,用于区分同一服务的不同实例。
除此之外当然还有Eureka相关的配置,类似与Server的配置,client也有serverUrl.defaultZone,registerWithEureka与fetchRegistry等配置。 额外一点是,有一个eureka.instance.preferIpAddress配置为ture,表示优先使用IP地址而不是主机名注册到Eureka中。
Why prefer an IP address?
因为在默认情况下,Eureka使用主机名来注册服务实例,这在基于服务器的环境中是没有问题的,但在容器化的环境中,主机名是随机生成的且没有DNS entries,所以如果不设置eureka.instance.preferIpAddress为true,那么Eureka将无法注册服务实例。
配置中最核心的一个触发配置就是registerWithEureka,这个配置决定了服务实例是否注册到Eureka中。 然后同时将fetchRegistry配置为true,表示从Eureka中获取注册信息缓存到本地,为之后的客户端负载均衡做准备。默认更新间隔为30s,可以通过eureka.client.registryFetchIntervalSeconds来修改。
默认情况下,这两者的配置属性就是true,所以不需要显式配置也能正常工作,这里只是为了说明这两个配置的作用。
最后,自然要通过eureka.serviceUrl.defaultZone来指定EurekaServer的地址。 可以配置多个EurekaServer地址,以逗号分隔,但仅仅这样还不够,还需要做一些额外的工作来让Eureka节点直接互相共享注册信息。
不过这一部分书中没有具体说明,仅仅是提到了一下,然后我查找了Spring官方的资料,在4.0版本后,只要在eureka配置中注册server自己,然后url选择另一个server即可实现互相共享注册信息。
Eureka’s REST API
要在REST API中看到一个服务的所有实例,请选择以下GET端点: http://<eureka service>:8070/eureka/apps/<APPID> APPID是服务的名称,也就是我们配置的spring.application.name。
其返回的结果这里就不贴了,可以自己试一下。
以及补充一点是,Eureka的REST API默认返回XML格式的数据,如果想要返回JSON格式的数据,可以在请求头中添加Accept: application/json。
当然有了REST API就自然少不了对其安全的配置,这里书中没有提到,但是在我之前附上的spring官方资料中有提到,也是很简单地引入spring-security做一些小工作即可。
Eureka dashboard
这个就不赘述了,直接访问Eureka的host地址即可。
作者补充了一点是服务注册需要花费一定的时间(30s),so Don’t be impatient
Using service discovery to look up a service
作者介绍了三种方式,其不断演进,从最低层次的抽象一直到集成客户端的负载均衡,分别是:
- Spring Discovery Client
- Spring Discovery Client-enabled REST template
- Netflix Feign client
Spring Discovery Client
Spring Discovery Client提供了最低程度的抽象。使用它,你可以通过服务名称来查找服务实例,然后使用服务实例的信息来构建URL。
作者的使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Autowired
private DiscoveryClient discoveryClient;
public Organization getOrganization(String organizationId) {
RestTemplate restTemplate = new RestTemplate();
List<ServiceInstance> instances = discoveryClient.getInstances("organization-service");
if (instances.size()==0) return null;
String serviceUri = String.format("%s/v1/organization/%s",instances.get(0).getUri().toString(), organizationId);
ResponseEntity< Organization > restExchange =
restTemplate.exchange(
serviceUri,
HttpMethod.GET,
null, Organization.class, organizationId);
return restExchange.getBody();
}
使用discoveryClient.getInstances("organization-service")来获取服务实例列表, 然后使用第一个实例的信息来构建URL,最后使用RestTemplate来调用服务。
作者指出,由于Spring Discovery Client是非常底层的,所以你最好有合适的场景需求再去使用它。 作者自己提出自己的做法中没有利用到负载均衡的好处,同时这一段代码做了太多的工作,一般来说不用直接拼接URL。
同时作者直接用new 关键字来创建RestTemplate,这是因为后面一小节的案例中,作者对自动注入的RestTemplate做了一些配置,所以这里就不用自动注入了。
总之,这种方式仅做了解。
a Load Balancer–aware Spring REST template
接着,作者使用了能够做到负载均衡的做法。
配置能够自动完成负载均衡的RestTemplate,很简单,因为SpringCloudLoadBalancer毕竟就是Spring家族的,所以只要一个注解即可,
1
2
3
4
5
6
// 在配置类或者启动类内
@LoadBalanced
@Bean
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
然后具体直接使用Eureka service ID 访问服务即可,不需要关注具体的ip与端口,底层构建具体URL的工作将会由SpringCloudLoadBalancer来完成。
1
2
3
4
5
6
7
8
9
10
11
12
@Autowired
RestTemplate restTemplate;
public Organization getOrganization(String organizationId){
ResponseEntity<Organization> restExchange =
restTemplate.exchange(
"http://organization-service/v1/organization/{organizationId}",
HttpMethod.GET,
null, Organization.class, organizationId);
return restExchange.getBody();
}
Netflix Feign client
SpringCloudLoadBalancer搭配的RestTemplate 之外的一个替代选项是Netflix Feign client。 其采用了不同的方式来调用REST服务。
(首先需要在程序启动类中添加@EnableFeignClients注解) 使用Feign client,在形式上我们需要定义一个接口,然后在接口上添加注解来指定服务名称,以及具体的服务路径。
1
2
3
4
5
6
7
8
@FeignClient("organization-service")
public interface OrganizationFeignClient {
@RequestMapping(
method= RequestMethod.GET,
value="/v1/organization/{organizationId}",
consumes="application/json")
Organization getOrganization(@PathVariable("organizationId") String organizationId);
}
除了接口上的@FeignClient注解中配置服务的注册名称外,剩下的代码和普通的SpringMVC Controller没有什么区别。 而最终要使用这个FeignClient,只需要在需要的地方注入即可,然后直接调用即可。
关于Feign还有很多其他东西,不过这些不太重要与本博文主题无关所以不展开了。
综合来说,Netflix Feign client是使用起来最简单方便的,而如果要一些更多的控制与自定义,那么可以选择其他两种方式。
Summary
- 使用服务发现来抽象 服务示例的具体物理位置
- Eureka是一个服务发现服务器,可以使得在完全不影响用户使用(无感知)的情况下,对服务进行扩容、缩容等操作
- 服务自身进行客户端的负载均衡(通过将信息进行缓存并以一定频率与服务发现组件进行同步)可以提高性能,增加了弹性
- 使用不同的方式来调用服务,可以是最底层的Spring Discovery Client,也可以是SpringCloudLoadBalancer搭配的RestTemplate,也可以是Netflix Feign client,三种方式抽象程度不断提高。