使用Spring WebFlux开发响应式API
在之前一节的Blog中介绍了响应式编程的基本架构-Reactor,以及响应式编程的基本概念,本博文将介绍使用Spring WebFlux( 一个基于Reactor的,抽象级别更高的架构)来开发响应式API。
SpringWebFlux
intro
先回顾一下已经很熟悉的SpringMVC,该框架是基于Servlet的,其本质上是阻塞与多线程的。
这一点很好理解,一个Http请求要被处理,就需要一个Thread来做这件事情。一个Thread同一时刻只能处理一个请求,如果有多个请求,就需要多个Thread来处理,这就是多线程。
接着,阻塞就是指,只有一个阶段的处理完全结束后,才会进行下一个阶段的处理。例如,对于一个Http请求,首先要读取请求内容,直到json数据被 完全 解析后,才会进行下一步的处理。同理,一些数据库操作,IO操作等都是阻塞的。
基于Servlet的方式自然是经过历史考验的.相关技术栈十分成熟,即使现如今 高并发 场景不断出现,也有一些新的解决方案例如NIO之类的被提出使用,Servlet仍然是网络开发的主流。( 但是也有一种说法是,现在很多高并发的解决,主要还是归功于计算机服务器硬件水平的提升,NIO线程池之类的贡献不大)
不论是那种解决方案,只要底层仍然是Servlet,那么其至少还有这一部分是阻塞的。而之前铺垫的响应式编程,其本质上是非阻塞的。最终,Spring基于Reactor响应式编程,提供了完全不同于Servlet的SpringWebFlux框架。
使用SpringMVC时, 你可能会发现其同样也能够接受响应式类型例如Mono Flux请求,但其本质上(在处理方法上)仍然是非响应式于阻塞的,因为其底层仍然是Servlet.
概念
SpringWebFlux实现非阻塞的方式是基于Reactor的,其本质上是事件驱动的。在SpringWebFlux中,一个Http请求的处理过程,就是一个事件流的处理过程。 基于此,相较于传统Servlet实现,一个最关键的区别是,在SpringWebFlux中,一个Thread可以处理多个请求,这就是非阻塞(异步)的本质。
具体来说,这归功于一种称作 event looping 的技术, 这种技术的实现方式是,一个Thread不断地轮询,检查是否有事件发生,如果有,就处理这个事件,如果没有,就继续轮询。
而处理行为本身也是异步的,即本Thread异步call另一个workingThread的回调,然后便去处理其他请求或继续轮询了,这个call本身又作为event在另一个lopping中被异步处理,这样层层嵌套,一个又一个looping成为一个完整的流。 等到异步call的方法执行完毕后,结果会流回来,Thread再接受回调结果做处理,中间没有阻塞。
最终的结果便是,一个Thread可以同时处理多个请求,而不需要创建多个Thread。
(当然仍需要创建MultiThread来完成工作,但是一个Thread能非阻塞地处理多个请求) 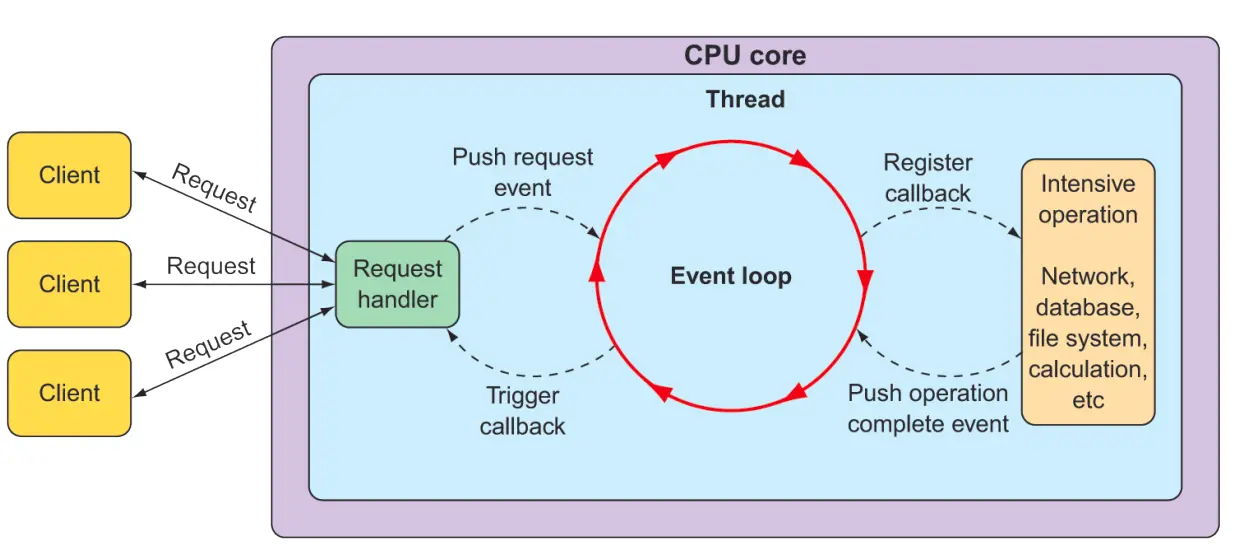
这样,异步 web 框架就能够使用更少的线程应对繁重的请求,从而实现更好的扩展性,相较于传统Servlet中往往使用的线程池方案,这种方式更加简洁高效( that’s what the author says)。
介绍
简单来说,由于WebFlux是基于Reactor而非Servlet的(无ServletAPI) ,其与SpringMVC在很多方面都有所不同。但在语义上,MVC是和实现无关的思想,所以WebFlux也可以用MVC范式( Controller - Service - Repository). 最终Spring的做法是,不将WebFlux完全融入SpringMVC,而是作为一个独立的框架,但是其与SpringMVC共享了顶层的API,例如@Controller、@RequestMapping 等注解,这样在使用上有很大的便利性。
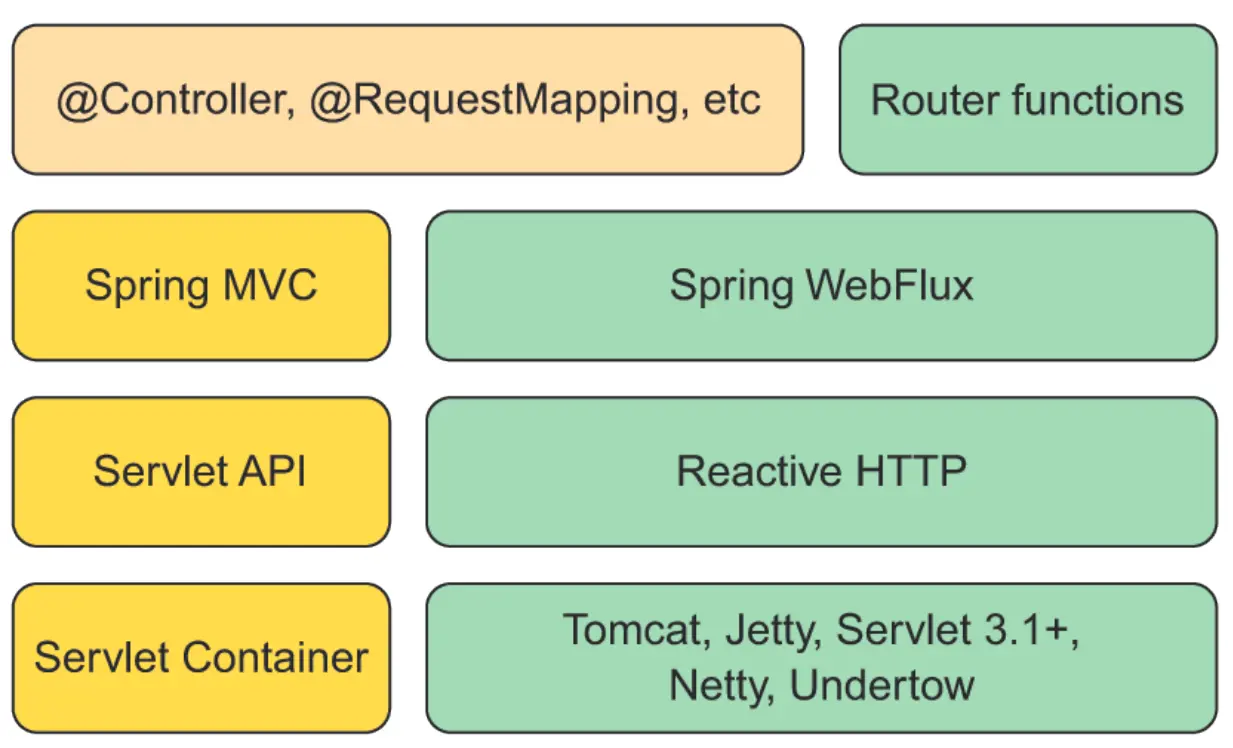
如图所示,WebFlux和SpringMVC的底层完全不同,(值得一提的便是无 ServletAPI与默认使用Netty而非Tomcat作为底层服务器) ,但是顶层的API是一致的,我们仍可以像使用SpringMVC一样,通过注解的方式来定义我们的API。 同时,你可能注意到了右上角的Router Functions,使用其可以用函数式编程的风格来创建API,这也是WebFlux区别于MVC的一大特色。 我们马上就开始这两种方法的介绍。
使用注解的方法来定义API
首先自然要引入依赖,这里不赘述了。
剩下的大部分也与SpringMVC创建Controller一样,毕竟注解是通用的。 注意一点要注意的便是,由于WebFlux是基于Reactor的,所以其接受的参数与返回值类型均需要是Mono或Flux。
1
2
3
4
@GetMapping(params="recent")
public Flux<Taco> recentTacos() {
return Flux.fromIterable(tacoRepo.findAll()).take(12);
}
在这一代码示例中,由于要符合WebFlux的规范,我们使用Flux的静态方法手动地将Iterable转换为Flux,然后使用take方法来限制返回的数量。
这一做法是可行的,但仔细想想,这并非是一个好的做法. 因为就像我们之前提到,在EventLooping中,所有的操作都是异步的事件,一个又一个looping组成了完整的流。而此处的这一操作是同步的与阻塞的,这样的编码会失去使用webFlux的意义。 在理论上,我们系统整体的每一个(MVC)组件中都通过响应式类型的数据进行数据传输,而我们定义的Controller接口是整个完整的事件流的最顶端。 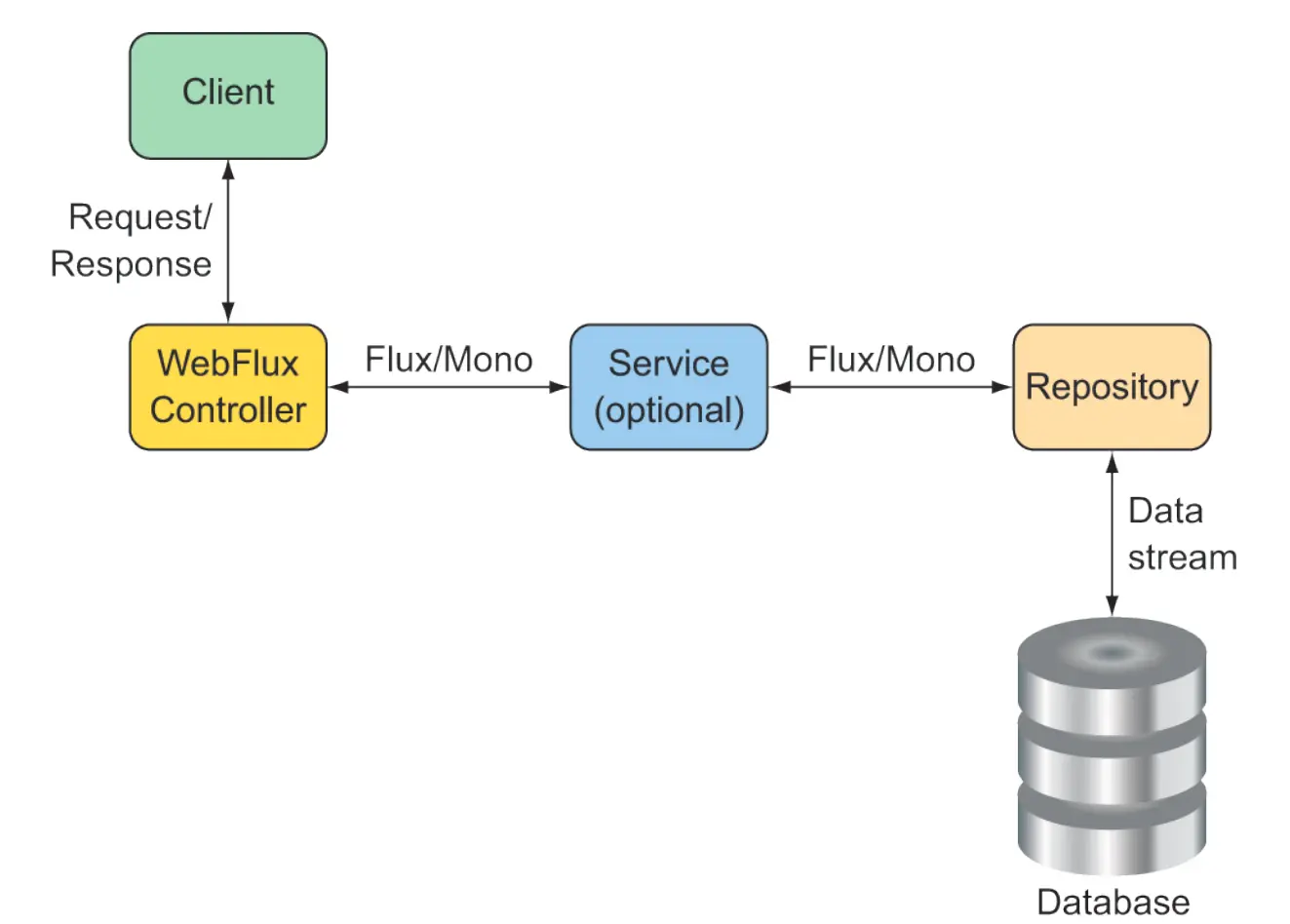
所以一个更好的做法是,让我们的Repository层直接返回的就是flux, 代码变更为
1
2
3
4
@GetMapping(params="recent")
public Flux<Taco> recentTacos() {
return tacoRepo.findAll().take(12);
}
至于如何实现这一点(让Repository直接返回Flux),我们在之后的博文 开发响应式的数据访问层 中会详细介绍。本文中我们仅仅关注Controller层的实现。
同样,对于入参来说,直接使用显式代码规定其为Mono或Flux类型是可行的,包括搭配@RequestBody、@RequestParam等注解使用。 除了数据类型的变更,其余所有的代码编写都和普通的SpringMVC一样,没有什么需要特别强调的。
在创建的API中,我们不需要显式地对Mono、Flux类型的消息进行Subscribe,因为Spring会自动帮我们完成这一步骤。但注意这仅仅是在Controller中的特性,在其他地方仍然需要手动Subscribe。在之后的响应式地消费REST API中你可以看到这一点。
使用函数式编程的方法来定义API
使用注解固然很方便,但是其是声明式的,我们无法直接看到其背后的逻辑。即使用注解,我们做的是what的工作,但是how这一层是封装在Spring中的,我们无法直接看到。 同时,我们在调试的时候也不能直接在注解上打断点,这一点也是不方便的。所以,为满足定制化与拓展话的需求,Spring 引入了一个新的函数式编程模型来定义响应式 API。
这个新的模型就是 Router Functions,其更像是一个库,而不是一个框架,允许您将请求映射到不带注解的处理代码 其主要包含4中类型的对象,分别是
- RequestPredicate
- RouteFunction
- ServerRequest
- ServerResponse
不多说了,直接看几个例子吧。
1
2
3
4
5
6
7
8
@Bean
public RouterFunction<?> helloRouterFunction() {
return route(GET("/hello"),
request -> ok().body(just("Hello World!"), String.class))
.andRoute(GET("/bye"),
request -> ok().body(just("See ya!"), String.class))
;
}
这是一个简单的示例,对于/hello的GET请求,返回Hello World!,对于/bye的GET请求,返回See ya!。
其中ok(),body()等方法均是Spring提供的静态方法,用于创建一个ServerResponse对象,
具体来说ok()方法创建的是一个状态码为200的ServerResponse对象,而body()方法则是将其body设置为just("Hello World!"),
just()方法则是Reactor中的静态方法,其创建一个Mono对象。 body()的第二个参数则是设置body的类型,这里是String.class。
andRoute()方法则是将两个路由函数连接起来,返回一个新的路由函数。这样就不用再创建一个新的路由函数了。
在一个实际的开发场景中,一个路由函数可能如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
@Configuration
public class RouterFunctionConfig {
@Autowired
private TacoRepository tacoRepo;
@Bean
public RouterFunction<?> routerFunction() {
return route(GET("/api/tacos").
and(queryParam("recent", t->t != null )),
this::recents)
.andRoute(POST("/api/tacos"), this::postTaco);
}
public Mono<ServerResponse> recents(ServerRequest request) {
return ServerResponse.ok()
.body(tacoRepo.findAll().take(12), Taco.class);
}
public Mono<ServerResponse> postTaco(ServerRequest request) {
return request.bodyToMono(Taco.class)
.flatMap(taco -> tacoRepo.save(taco))
.flatMap(savedTaco -> {
return ServerResponse
.created(URI.create(
"http://localhost:8080/api/tacos/" +
savedTaco.getId()))
.body(savedTaco, Taco.class);
});
}
}
其中,我们将响应信息的创建与路由函数分离开来,这样可以使得代码更加清晰。
同时,不同于注解的方式,我们可以对api的每一步进行更加细粒度的控制,每一个操作也都是显式地,这样我们可以更加清晰地看到整个流程。也方便了调试。
对响应式API进行测试 - WebTestClient
单元测试
一般流程就是 使用Mockito来模拟Repository层,然后使用WebTestClient来模拟请求,最后使用Mockito来验证结果。
使用mockito需要自定义一些测试数据,例如直接在测试方法中硬编码,或者读一个json文件等等。 一般mockRepository的流程如下:
1
2
TacoRepository tacoRepo = Mockito.mock(TacoRepository.class); // 定义mock对象
when(tacoRepo.findAll()).thenReturn(tacoFlux); // 定义mock对象的行为
使用WebTestClient来模拟请求的流程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
WebTestClient testClient = WebTestClient.bindToController(
new TacoController(tacoRepo))
.build(); // 创建测试客户端,需要绑定一个Controller
// 发送请求进行测试
testClient.get().uri("/api/tacos?recent")
.exchange()
.expectStatus().isOk()
// 验证返回数据是否符合预期
.expectBody()
.jsonPath("$").isArray()
.jsonPath("$").isNotEmpty()
.jsonPath("$[0].id").isEqualTo(tacos[0].getId().toString())
.jsonPath("$[0].name").isEqualTo("Taco 1")
.jsonPath("$[1].id").isEqualTo(tacos[1].getId().toString())
.jsonPath("$[1].name").isEqualTo("Taco 2")
.jsonPath("$[11].id").isEqualTo(tacos[11].getId().toString())
.jsonPath("$[11].name").isEqualTo("Taco 12")
.jsonPath("$[12]").doesNotExist();
}
testClient有需要方法,可以用于发送不同的请求,也有很多except方法用于验证数据,这里不一一展开。
仅补充一处,当一个响应的json很复杂是,可以用json方法替换jsonPath,其接受一整个表示Json的String做比较。
1
2
3
4
5
6
7
8
9
ClassPathResource recentsResource = new ClassPathResource("/tacos/recent-tacos.json");
String recentsJson = StreamUtils.copyToString( recentsResource.getInputStream(), Charset.defaultCharset());
testClient.get().uri("/api/tacos?recent")
.accept(MediaType.APPLICATION_JSON)
.exchange()
.expectStatus().isOk()
.expectBody()
.json(recentsJson);
或者是用ExpectBodyList方法,其接受一个List
1
2
3
4
5
6
testClient.get().uri("/api/tacos?recent")
.accept(MediaType.APPLICATION_JSON)
.exchange()
.expectStatus().isOk()
.expectBodyList(Taco.class)
.contains(Arrays.copyOf(tacos, 12));
更多测试略,可以参考书中的代码。
集成测试
使用@SpringBootTest注解,可以将测试类与SpringBoot应用程序集成起来,这样就可以直接使用@Autowired来注入集成的测试对象了。 集成测试中,不需要手动创建WebTestClient,使用自动注入即可。其他的没有什么区别。
响应式地消费 REST API
之前可以通过RestTemplate等对象来消费REST API,但是这些对象都是阻塞的,如果想要响应式地消费REST API,SpringWebFlux提供了WebClient对象。其可以理解为是RestTemplate的响应式版本。
WebClient 的常用使用方法有以下几种:
- 创建一个 WebClient 实例(或者注入一个 WebClient Bean)
- 指定发送请求的 HTTP 方法
- 指定请求中所必要的 URI 和 header
- 提交请求
- 消费响应
对应之前的tips,在使用WebClient要注意,最终要对其创建的Mono或者Flux进行订阅,才能使得请求真正发出去。 之前controller中的方法Spring会自动订阅,所以我们不需要手动订阅。
接下来就直接看代码示例吧
Get
1
2
3
4
5
6
7
Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8080/ingredients/{id}", ingredientId)
.retrieve()
.bodyToMono(Ingredient.class);
ingredient.subscribe(i -> { ... });
一个技巧是定义注入的Webclient时,为其指定一个baseUrl,这样就不需要在每次请求时都指定完整的url了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Bean
public WebClient webClient() {
return WebClient.create("http://localhost:8080");
}
-----------
@Autowired
WebClient webClient;
public Mono<Ingredient> getIngredientById(String ingredientId) {
Mono<Ingredient> ingredient = webClient
.get()
.uri("/ingredients/{id}", ingredientId)
.retrieve()
.bodyToMono(Ingredient.class);
ingredient.subscribe(i -> { ... });
}
网络并不是始终可靠的,或者并不像您预期的那么快,远程服务器在处理请求时有可能会非常缓慢。理想情况下,对远程服务的请求会在一个合理的时间内返回。无法正常返回的话,客户端要是能够避免陷入长时间等待响应的窘境就好了。为了避免客户端请求被缓慢的网络或服务阻塞,您可以使用 Flux 或 Mono 的 timeout() 方法,为等待数据发布的过程设置一个时长限制。作为样例,您可以考虑一下如何为获取配料数据使用 timeout() 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
Flux<Ingredient> ingredients = webclient
.get()
.uri("/ingredients")
.retrieve()
.bodyToFlux(Ingredient.class);
ingredients
.timeout(Duration.ofSeconds(1))
.subscribe(
i -> { ... },
e -> {
//handle timeout error
});
Post
1
2
3
4
5
6
7
8
9
10
Ingedient ingredient = ...;
Mono<Ingredient> result = webClient
.post()
.uri("/ingredients")
.bodyValue(ingredient)
.retrieve()
.bodyToMono(Ingredient.class);
result.subscribe(i -> { ... });
这是Post一个非响应式数据的方法,如果要Post一个Flux或者Mono,可以使用body方法,其接受一个Publisher对象。
1
2
3
4
5
6
7
8
9
10
Mono<Ingredient> ingredientMono = Mono.just( new Ingredient("INGC", "Ingredient C", Ingredient.Type.VEGGIES));
Mono<Ingredient> result = webClient
.post()
.uri("/ingredients")
.body(ingredientMono, Ingredient.class)
.retrieve()
.bodyToMono(Ingredient.class);
result.subscribe(i -> { ... });
剩下的几种请求方法的与之类似,这里就不一一展开了。
处理错误
请求远程服务时,可能会出现各种各样的错误,比如网络错误,服务错误等等。WebClient提供了一些方法来处理这些错误。 我们需要在WebClient定义的Publisher中,使用onStatus方法对错误进行处理。
1
2
3
4
5
6
7
Mono<Ingredient> ingredientMono = webClient
.get()
.uri("http://localhost:8080/ingredients/{id}", ingredientId)
.retrieve()
.onStatus(HttpStatus::is4xxClientError,
response -> Mono.just(new UnknownIngredientException()))
.bodyToMono(Ingredient.class);
这里仅仅做一个演示,将异常对象传递给Mono,实际上我们可以在onStatus方法中做任何我们想做的事情,比如记录日志,或者是其他更复杂的处理。
同时,onStatus的第一个参数使用了一个方法引用,来根据响应的状态码判断是否为异常。这里我们还可以使用任意的自定义的返回Boolean的方法来判断是否为异常。如下例所示
1
2
3
4
5
6
7
Mono<Ingredient> ingredientMono = webClient
.get()
.uri("http://localhost:8080/ingredients/{id}", ingredientId)
.retrieve()
.onStatus(status -> status == HttpStatus.NOT_FOUND,
response -> Mono.just(new UnknownIngredientException()))
.bodyToMono(Ingredient.class);
最终在subscribe时,可以对返回的Mono进行判断,如果是异常,可以在客户端进行一些处理
1
2
3
4
5
6
7
8
9
ingredientMono.subscribe(
ingredient -> {
// handle the ingredient data
...
},
error-> {
// deal with the error
...
});
exchange 与 retrieve
之前我们使用的都是retrieve方法,其会自动将响应的body转换为Mono或者Flux。但是有时候我们需要对响应的header进行处理,这时候就需要使用exchange方法了。
1
2
3
4
5
6
7
8
9
10
Mono<Ingredient> ingredientMono = webClient
.get()
.uri("http://localhost:8080/ingredients/{id}", ingredientId)
.exchangeToMono(cr -> {
if (cr.headers().header("X_UNAVAILABLE").contains("true")) {
return Mono.empty();
}
return Mono.just(cr);
})
.flatMap(cr -> cr.bodyToMono(Ingredient.class));
简单来说,retrieve是对exchange的封装,其会自动将ClientResponse转换为我们需要的Mono或者Flux。是一种抽象层级更高,更加简单的使用方式。
exchange是比较底层的方法,其返回的是一个ClientResponse对象,我们可以对其进行任意的处理,然后再使用flatMap方法将其转换为我们需要的Mono或者Flux。当我们需要做一些比较复杂的处理时,可以使用exchange方法。
响应式Api如何使用SpringSecurity
简单来说,SpringSecurity完成了出色的工作,其可以在响应式的WebFlux应用中,提供与传统的SpringMVC应用中相同的安全特性。 ( 不需要修改依赖) 具体在配置上,其思路与在SpringMVC项目中类似,只需要做一些小的改动即可。
如果记忆生疏,可以参考之前的博文SpringSecurity 回顾如何在SpringMVC中使用SpringSecurity
网络配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Configuration
@EnableWebFluxSecurity // 启用WebFlux安全
public class SecurityConfig {
@Bean
public SecurityWebFilterChain securityWebFilterChain(ServerHttpSecurity http) {
return http
.authorizeExchange()
.pathMatchers("/api/tacos", "/orders").hasAuthority("USER")
.anyExchange().permitAll()
.and()
.build();
}
}
注意点:均为一些细节
- 与SpringMVC中的@EnableWebSecurity不同,这里使用的是@EnableWebFluxSecurity
- 使用的是ServerHttpSecurity,而不是HttpSecurity
- 使用的是SecurityWebFilterChain,而不是SecurityFilterChain
- 使用的是ServerHttpSecurity的authorizeExchange方法,而不是authorizeRequests
- 最后显式调用build方法
UserDetails配置
1
2
3
4
5
6
7
8
9
10
11
12
13
@Service
@Bean
public ReactiveUserDetailsService userDetailsService( UserRepository userRepo) {
return new ReactiveUserDetailsService() {
@Override
public Mono<UserDetails> findByUsername(String username) {
return userRepo.findByUsername(username)
.map(user -> {
return user.toUserDetails();
});
}
};
}
- 需要实现的接口是ReactiveUserDetailsService,而不是UserDetailsService
- 返回的是Mono
,而不是UserDetails
其余的没有什么区别
总结
- Spring WebFlux 提供了一个响应式 web 框架,其编程模型类似 Spring MVC,共享了许多相同的注解。
- Spring 还提供了一个函数式编程模型 RouterFunction 作为 注解式编程模型的补充。
- 响应式控制器可使用Spring提供的 WebTestClient 进行测试。
- 对于消费RESTAPI,Spring 提供了 WebClient,可以将其立即为RestTemplate的响应式版本。
- 尽管SpringWebFlux底层有很大改变,但是SpringSecurity可以在响应式应用中提供与传统SpringMVC应用中相同的安全特性。配置上也只需要做一些小的改动即可。