SpringBoot开发微服务应用的三个视角 - 架构、开发与运维
在实际的开发场景中,仅仅只靠单一类型的技术人员是无法完成整个应用的交付的,即同一应用会涉及到纳入多个角度的问题. 一般来说,一个成功的微服务开发始于三种关键角色的视角。
- 架构师: 从整体上看待应用,负责应用的整体架构设计,以及各个微服务之间的交互。
- 开发工程师: 负责实现微服务具体的业务逻辑.
- 运维工程师(DevOps): 在生产与非生产环境中,决定的服务的部署与管理方式. 关键点为保证每一个环境中服务的 一致性和可重复性。
本博文为原书第三章节的精要,将会具体从上述三个角色的视角来讲述如何设计与构建一组微服务。
架构师视角 - 设计微服务架构
架构师在软件工程中的作用是提供一个针对要解决的问题的工作模型。
架构师提供了一个脚手架,开发人员可以根据这个脚手架构建他们的代码,从而使应用程序的所有部分都能够协同工作。
构建微服务架构时,架构师需要考虑以下几个核心任务:
- 业务问题的拆解
- 确定服务粒度
- 定义服务接口
拆解业务问题
当面对复杂的问题是,大多人尝试将问题分解为更小的可管理的部分。这样做就可以先不同考虑每个部分的细节,而是先寻找这些核心部分之间的关系。
在微服务架构的设计中,其差不多也是同样的步骤。架构师将实际的业务问题分解为更小部分,其表示了业务问题中离散的几个活动。 这些部分封装了业务规则与某一特定领域相关的数据逻辑,在概念上作为后续微服务节点实现的一个候选模型。
例如,一个业务流中会同时设计到顾客、商品与订单三个概念,那么这三个概念就是业务问题的拆解结果。
将业务领域进行拆分是一个没有标准答案的过程,但是可以参考以下几个原则:
- 留意对业务问题描述中的名词:
当对某些名词一遍又一遍地提及揭示了其可能是一个核心的业务对象,并有可能是一个微服务的候选项。 - 以及动词交互:
动词强调了服务的行动,并经常直接划分了业务对象的自然轮廓。 例如 “交易X需要从 A 与 B 中获得数据”, 这通常意味着存在多个服务对象需要被创建 - 注意数据是凝聚在一起的:
当讲业务问题差分时,注意不同的数据之间应当是高度关联的。 如果在谈论时,一个新的数据类型不知道从哪里冒出来了,那么往往该数据属于另一个新的业务对象。 注意,微服务必须是完全自治的。
书中接下来具体介绍了 其展示项目的架构 - 包括 组织、许可、合同、资产等领域的拆分,这里便不具体展开了。
确定服务粒度
当有了一些简单的数据模型后,既可以开始定义应用程序中将会有哪些微服务了。 主要的目标就是将模型中提取出功能并将其融入到 可以独立部署,完全自治的微服务中。 这些微服务单元可以选择共享或者拥有独立的数据库。但是注意,即使是共享数据库,微服务的划分还需要具体划分到表级别。
在确定表级别的微服务后,可以开始考虑微服务的粒度了。 微服务的粒度是一个非常主观的问题,而太粗粒度或者太细粒度(coarse/fine grained)都会很麻烦. 以下是一些可以参考的原则:
- 在设计初期,从粗粒度开始迭代,不要过度设计。
在开始设计微服务的时候,很容易进行过度设计,这将导致过多的微服务组件,而其也许并不是真正需要的。 - 重点先关注与服务之间是如何交互的,而不是实现细节。
这将帮我们很容易地建立一个服务的粗略轮廓,而不是陷入实现细节的泥潭。而且,即使当设计的粒度不够细的时候,也可以很容易地将其细化。 - 注意服务的职责会随时间以及对业务的理解而变化。
服务的职责会随着时间的推移而变化,这是很正常的。因此,不要过度设计,而是在需要的时候进行调整。
注意,当出现这些症状时,说明服务的粒度可能过于粗或细了
- 一个服务有太多的职责需要承担
- 一个服务有 许多数据库表的 权限
一般来说,一个服务涉及到的数据库表应当不超过3-5张,否则就需要考虑将其拆分了。 一个服务有大量的测试用例需要编写
一个服务可能在定义之初是合适的,但是随着时间的推移,其职责可能会变得越来越多,一个针状就是出现了大量的测试用例。- 一个服务所做的事情只是简单的CRUD
这是最典型的服务粒度过于细的表现。 - 某些服务之间的联系太过紧密,耦合度太高
有时候某些微服务之间不停地进行交互,也许这是因为其职责太过紧密,需要考虑将其合并。
总的来说,对于微服务架构的设计,需要在粗粒度与细粒度之间进行权衡,而且这个过程是一个不断迭代的过程。 同时也需要注意,微服务的粒度是一个主观的问题,不同的人可能会有不同的看法,这也是正常的。 往往需要在实践中不断地进行调整。有时候也存在设计向物理限制妥协的情况,例如,如果一个服务的粒度过于细,那么其部署将会非常麻烦。 总之,最终而言,实践是检验真理的唯一标准,应当采取一种务实的做法,而不是花费太多的时间在设计一个完美的架构上。
定义服务接口
这一部分就不追逐了,书中主要讲的是 术 的部分(暴露为REST,使用JSON通信),这些应该都是很熟悉的了。
由于没有具体的场景,对 道 原书在本节没有具体讨论,仅提到了一个原则:
别搞太复杂,尽量一眼看懂
架构设计补充 - 什么时候不要使用微服务
构建分布式系统本身带来更多的复杂性(值得吗)
微服务架构从本质上来说是一种分布式系统,而分布式系统引入了很多无法避免的复杂性. 这将需要更高水准的开发与操作的成熟度。
注意,微服务架构并不是一个缺省方案,除非真的需要,并且组织方有意愿在自动化与监视、拓展方面上有投资,否则不要使用它。
(软件的维护与管理成本最终一定会大幅超过开发成本,而微服务架构的应用更是如此)
虚拟服务器或容器的泛滥
容器化部署是最常见的微服务模式之一,而在具体的生产场景中,我们往往最终会有50-100个容器在运行。 即使这些容器的runtime cost很低,但是管理这些容器的成本也是非常高的。
(当然可以进行权衡, 使用其他部署方式,例如FaaS来降低成本,但最终还是要看具体的场景)
应用程序本身的类型适合微服务吗
微服务架构并不是一个万能的解决方案,其擅长的是大型的、复杂的、长期运行的应用程序。 其可以提供弹性特性并方便拓展。
但是如果应用程序本身是一个简单的、短期运行的、不需要弹性特性的应用程序,那么微服务架构就是一个过度设计了。 最终构建出来的系统所带来的额外复杂度可能并不能 与其带来的好处 相抵消。
实际上,许多知名的网络服务(或其子组件)仍然使用单体架构,而且运行得非常好。
数据需要强一致性的场景 - 交易型应用
微服务本身通常只包装少量的数据表与针对其的操作,而且这些操作通常是原子的。
如果应用程序本身需要对数据进行复杂的聚合与转换操作。那么微服务架构会让这些操作变得非常复杂。 并且微服务本身也将无一例外地承担过多的职责出现性能问题。
开发工程师视角 - 使用SpringBoot构建微服务
SpringBoot controller - 微服务的入口
略, 相关内容在SpringBoot中已经非常熟悉了
补充 - Endpoint names matter
- 使用明确的URL名称确定服务所代表的资源,保持与内部变量名称的一致性
- 可以在URL中建立资源之间的关系来避免创建单独的子节点,例如
/customers/{customerId}/orders/{orderId},但注意,当这种做法产生的URL过长时,应当考虑使用查询参数来代替,(或考虑是否承担了过多的责任) - 尽早地使用版本管理方案,常见的模式是在所有的端点前添加版本号。例如
/v1/customers/{customerId}/orders/{orderId}
国际化支持
当需要提供多种格式和语言的内容是,国际化是一个非常重要的问题。 Spring提供了一个简单的解决方案,通过简单地注入几个Bean就可以实现国际化支持。
服务端的思路很简单,从一个地方获取到locale信息,然后再根据该信息获取到对应的资源文件,用这些特定的资源文件来替换掉原来的文本即可。
具体在代码上,需要注入一个LocaleResolver,然后在controller中使用@RequestHeader 注解来获取到locale信息,最后使用MessageSource来获取到对应的资源文件即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Bean
public LocaleResolver localeResolver() {
SessionLocaleResolver localeResolver = new SessionLocaleResolver();
localeResolver.setDefaultLocale(Locale.US);
return localeResolver;
}
@Bean
public ResourceBundleMessageSource messageSource() {
ResourceBundleMessageSource messageSource = new ResourceBundleMessageSource();
messageSource.setUseCodeAsDefaultMessage(true);
messageSource.setBasenames("messages");
return messageSource;
}
注入的LocaleResolver中配置了缺省的locale为US,
MessageSource中配置了资源文件的名称为messages,且当对应的国际化支持信息不存在时,使用源码直接作为默认的信息。
接着自然就是完成国际化支持的消息文件本身了,因为配置了Basename为message,所以不同语言地区版本的文件名应该为messages_en.properties,messages_zh.properties 等等。
例如在messages_es.properties文件中定义如下信息(西班牙语)
1
license.delete.message=Eliminando licencia con id %s para la organization %s
在要使用的地方,注入MessageSource,然后使用getMessage方法来获取到对应的信息即可。
参数一般传递3个,message在property文件中的key,此处为license.delete.message,
第二个参数为一个数组,用来替换掉message中的占位符,
第三个参数为locale信息,用于获取到不同的语言版本的信息。
1
2
3
String responseMessage = null;
responseMessage = String.format(messages.getMessage("license.delete.message", null, locale),licenseId, organizationId);
return responseMessage;
这里作者没有使用MessageSource自带的占位符填充,而是使用了String的format方法
我们现在可以由不同的locale来构建不同的message来支持国际化了 但是,locale信息本身是如何获取到的呢?一个最常用的做法是在请求头中添加一个Accept-Language的header,其值为en或zh 等等,这样就可以在controller中使用@RequestHeader注解来获取到locale信息了。
Controller中具体的代码如下
1
2
3
4
5
@GetMapping
public ResponseEntity<String> someMethod(
@RequestHeader(value = "Accept-Language", required = false) Locale locale) {
...
}
实际上获取locale的做法是很自由的,以上只是缺省做法,例如可以和前端沟通好,让前端处理后,可以直接将locale信息作为请求参数传递过来,这样就不需要在请求头中添加
Accept-Language的header了
提供REST的HATEOAS支持,来让客户端更好地使用服务
HATEOAS stands for Hypermedia as the Engine of Application State. Spring HATEOAS 可以让我们的API附带一些额外的信息,这些信息可以让客户端更好地使用服务。 HATEOAS的核心思想是,客户端不需要记住所有的URL,而是通过服务端返回的信息来获取到下一步的操作。
HATEOAS不是项目开发的必选项,但如果想要提供一个附带完成操作指南的API,遵循HATEOAS规范是一个很好的选项。
引入依赖
使用spring-boot-starter-hateoas
准备工作 - 让返回的资源类继承RepresentationModel<>
书中原本的一个REST节点返回的是一个 自定义的License类,为了支持HATEOAS,需要让其继承RepresentationModel<> ,这样就可以使用HATEOAS的相关功能了,泛型参数为自定义的License类
1
2
3
public class License extends RepresentationModel<License> {
...
}
当然这不影响License类本身的使用,只是让其支持了HATEOAS的相关功能而已。 License也可以继续正常地被ResponseEntity包装,返回给客户端。
在继承了RepresentationModel<>之后,对象就可以使用add方法来添加相关的信息了, 具体来说就是使用LinkTo方法来添加相关的链接信息,具体代码示例在下一节展示。
修改Controller中的方法
现在假设除了返回一个License对象之外,还需要返回更多遵循HATEOAS规范的信息,例如下一步的操作指南等等。 可以重构Controller中的代码如下:
1
2
3
4
5
6
7
8
9
10
License license = licenseService.getLicense(licenseId, organizationId);
license.add(
linkTo(methodOn(LicenseController.class).getLicense(organizationId, license.getLicenseId())).withSelfRel(),
linkTo(methodOn(LicenseController.class).createLicense(organizationId, license, null)).withRel("createLicense"),
linkTo(methodOn(LicenseController.class).updateLicense(organizationId, license)).withRel("updateLicense"),
linkTo(methodOn(LicenseController.class).deleteLicense(organizationId, license.getLicenseId())).withRel("deleteLicense")
);
return ResponseEntity.ok(license);
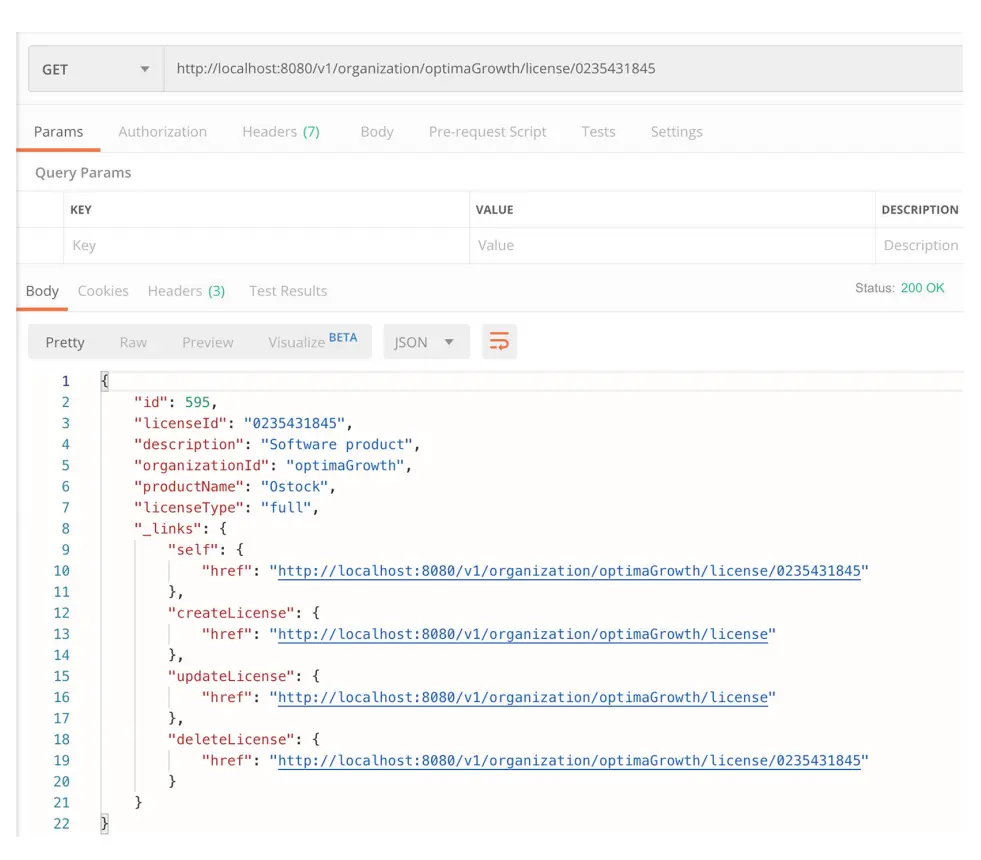
效果如下:
DevOps视角 - 构建应用与应对运行时环境带来的挑战
对DevOps来说,对于微服务架构的设计所需要的考虑全部都关于如何在服务进入生产环境后进行更好的管理。 对于微服务架构来说,写代码是简单的工作部分,而保持服务的可用性和稳定性才是真正的挑战。
之后的内容将会 依据下述几个原则进行谈论
- 一个微服务需要是自治的
即服务本身在启动或是停止后 多个微服务实例 可以 通过单一的软件工件 进行独立部署 - 一个微服务应该是可进行配置的
当服务启动后,其最开始应当是无状态的,其状态应当由外部的配置文件来决定,且这一过程由服务示例自己完成,无需人为干预 - 一个微服务实例 本身应该是对客户端透明的
客户端(用户本身与其他微服务节点本身作为消费者)不应该知晓服务的确切位置,微服务应该与服务发现组件进行交流,这样客户端就可以通过服务发现组件来获取到服务而不是通过具体的物理地址。 - 一个微服务实例 应该对其本身的健康状态进行交流
这是整个微服务架构中十分重要的一件事。 因为任何服务实例都有宕机的可能,所以需要有一种机制来让其他服务实例知晓这一情况,从而可以将请求转发到其他的服务实例上。具体在书中,其使用SpringBootActuator来实现这一功能。
以上原则仿佛与 微服务架构设计本身的理念相悖:微服务节点本身应该在规模与范围上尽可能小,但是为了满足上述原则,节点 本身又不得不添加一些额外的功能,这样就会导致节点本身的规模变高,且协同的难度也会变高,这些都会导致更多潜在的坑进而进一步增加了微服务失败的风险。
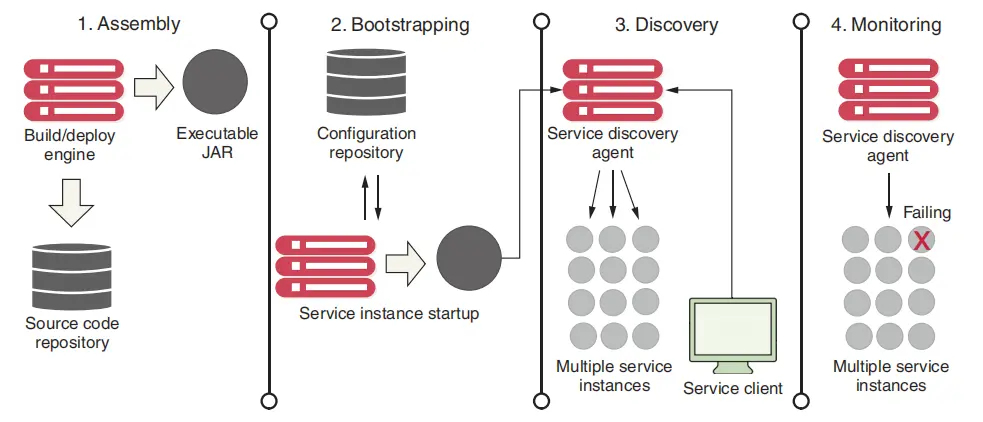
以DevOps的角度来看,我们需要在前期解决这些微服务的操作问题,同时将以下四个原则贯彻到每一次的微服务构建与部署中:
- 服务组装
如何打包与部署微服务以确保重复性与一致性,即让每一个微服务的代码与配置都是一致的 - 服务启动
如何将配置与代码分离,让服务在启动时可以自动完成配置而不需要人为干预 - 服务注册/发现
当一个新的微服务实体被添加后,如何让其他微服务实体知晓这一变化,从而可以将请求转发到新的微服务实体上 - 服务监视
需要监控微服务实例,以确保任何故障都可以被及时发现并进行处理
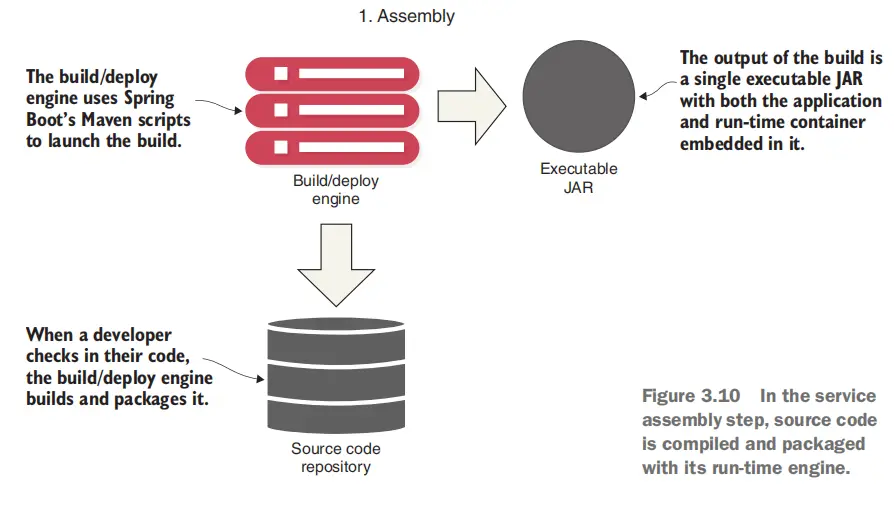
服务组装
从DevOps的角度来看,微服务架构背后最关键的一点就是 服务本身可以被快速部署应对环境的变化 (例如,如有涌入的用户需求,基础设施出现了问题等等)
为了做到这一点,微服务必须被打包成一个可以被安装的单独工件,同时其内部定义了所有的依赖关系且这些依赖包含了运行时引擎( 例如Http服务器或应用容器)
幸运的是,SpringBoot配置Maven可以很简单地完成这一工作,一般只需要执行 mvn package即可。
在传统的将程序部署到应用服务器的做法中, 服务器的配置往往没有源控制,而是通过人工使用用户界面和自制的管理脚本进行配置。 这种应用服务器配置与应用程序本身的分离会在部署过程中引入一些隐藏的失败点,很容易导致服务器出现配置漂移,进而引发表面上看似随机的中断问题。 而通过将运行时引擎封装到应用程序本身进行部署,与统一对配置管理,可以避免这些问题。
服务启动 - 进行配置

在软件开发过程中很常见的一个场景是要 让运行时的程序可以进行配置。一般包括读取配置文件或是从外部获取配置信息等等。
在微服务架构中,这一过程也是必不可少的,但是由于微服务架构中的服务实例数量往往是成百上千的,所以这一过程的复杂度也会随之增加。 同时,不仅仅是数量上,很多时候不同微服务之间还有地理位置上的分散的特点。所以,仅仅只用离线的配置文件来进行配置是不够的,使用外部配置中心是必不可少的。
但微服务中的配置中心需要解决一些独特的挑战
- 配置数据本身的结构往往是很简单的,且其是一种经常读,但很少写操作的数据。使用关系型数据库对配置信息进行保存是overkill的,会引入额外的复杂度, 配置信息本身只是简单的键值对。
- 数据读取的延迟需要低,因为节点需要快速启动
- 配置中心需要是高度可用的,其是一个重要的组件,因为一旦出错就变成了单点故障
在书的第五章,会具体讲解如何使用SpringCloudConfig来解决这些问题。
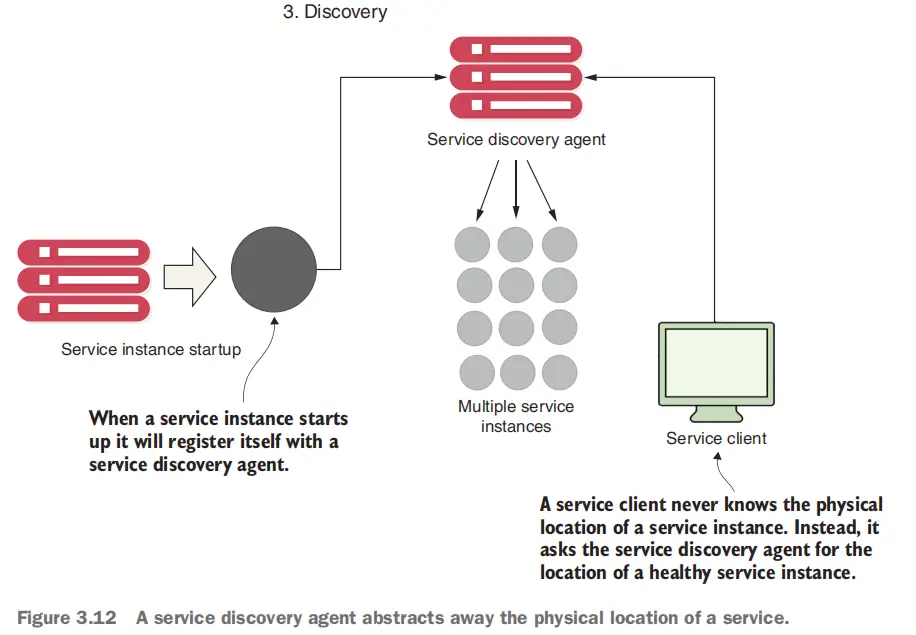
注册与发现
从微服务消费者(直接的用户,或者其他微服务断点)的视角出发,一个微服务的地址应该是透明的。 因为记住每一个微服务的地址是不现实的,同时微服务节点的生命周期往往不是很长(任何变化发生后需要重新部署注册) ,所以微服务本身的地址也会经常发生变化。 这固然是为了让微服务更加灵活,具有弹性来应对变化,但这也让管理微服务的地址池变成一个问题。
为了解决这个问题,我们需要一个服务注册中心,它可以让微服务在启动时将自己的地址注册到注册中心(具体为自身的物理地址 + 用于找到自己的逻辑地址),同时在微服务的地址发生变化(或是健康发生变化)时,注册中心也能够及时感知到这一变化。
沟通自己的健康状态
服务注册与发现组件仅仅是一个领路人的角色,我们还需要一个监视器来监视微服务的健康状态,以便在微服务出现故障时能够及时发现并进行处理。 (虽然服务注册与发现组件一定程度上可以做到监视,但为了不让器承担太多的职责,我们还是需要一个专门的监视器)
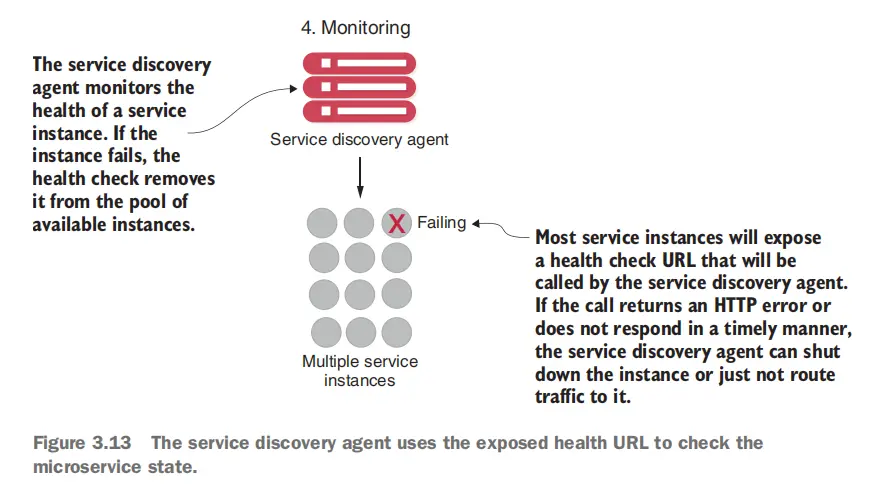
在使用REST的微服务中,最简单的暴露自身健康状态的方式就是使用HTTP端点,这样监视器就可以通过HTTP请求来获取微服务的健康状态。 如何计算微服务的健康状态,以及如何暴露这些信息,这些一般是开发者的职责(使用SpringBootActuator可以轻松搭建级基本骨架)。 对于DevOps来说,他们需要做的是将这些信息收集起来,然后进行监视,并进行相应的处理。
总结 - 结合三者的视角
从微观角度看,微服务架构似乎很简单,但要成功地将其应用到生产环境中,我们需要结合 架构师、开发者和DevOps三者的视角来进行设计。 三者视角关键的启示如下:
- 架构师: 关注业务问题的自然轮廓,在不断地描述与探讨商业问题的时候,留意那些可以被划分为微服务的边界。注意在最开始的时候, 粗粒度的划分是可以接受的,因为在后续的迭代中,可以将粗粒度的微服务再进行细分。一个好的架构往往是不断迭代的结果,而不是一蹴而就的。
- 开发者: 一个单一的微服务节点本身可以很小,但这并不意味着好的设计原则就被抛出窗外。在设计微服务时,仍需注意高内聚、低耦合等原则。专注于建立一个分层的服务并让其每一层都有不连续的责任。 避免在微服务中引入frameworks,因为过早的框架设计会大量增加维护成本.尽量让每一个微服务完全独立
- DevOps: 微服务不是来无影去无踪的,需要尽量设计完成的生命周期。除了关于自动构建与部署,还需要考虑如何监视微服务的健康状态,并在出错时进行处理。维护微服务往往比编写业务逻辑需要更多的工作与深思熟虑。